Linear Regression in Python with Cost function and Gradient descent

Machine learning has Several algorithms like
- Linear regression
- Logistic regression
- k-Nearest neighbors
- k- Means clustering
- Support Vector Machines
- Decision trees
- Random Forest
- Gaussian Naive Bayes
Today we will look in to Linear regression algorithm.
Linear Regression:
Linear regression is most simple and every beginner Data scientist or Machine learning Engineer start with this. Linear regression comes under supervised model where data is labelled. In linear regression we will find relationship between one or more features(independent variables) like x1,x2,x3………xn. and one continuous target variable(dependent variable) like y.
The thing is to find the relationship/best fit line between 2 variables.
if it is just between the 2 variables then it is callled Simple LinearRegression. if it is between more than 1 variable and 1 target variable it is called Multiple linearregression.
Equation:
1. for simple linear regression it is just
y = mx+c , with different notation it is
y =wx +b.
where y = predicted,dependent,target variable. x = input,independent,actual
m(or)w = slope, c(or)b = bias/intercept.

2. for mulitple linear regression it is just the sum of all the variables which is summation of variables like x1,x2,x3………xn,with weights w1,w2,w3...wn. to variable y.
y = w1.x1 + w2.x2 + w3.x3…………wn.xn + c
with summation it is
y= summation(wi.xi)+c, where i goes from 1,2,3,4……….n

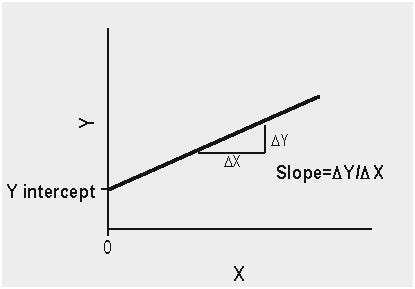
m = slope, which is Rise(y2-y1)/Run(x2-x1).
you can find slope between 2 points a=(x1,y1) b=(x2,y2). allocate some points and tryout yourself.
Realtime examples:
- predicting height of a person with respect to weight from Existing data.
- predicting the rainfall in next year from the historical data.
- Monthly spending amount for your next year.
- no.of. hours studied vs marks obtained
as i said earlier our goal is to get the best fit line to the given data.
But how do we get the Best fit line?
yes, its by decreasing the cost function.
But, how do we find the cost funtion?
Cost function:
a cost function is a measure of how wrong the model is in terms of its ability to estimate the relationship between X and y.

here are 3 error functions out of many:
- MSE(Mean Squared Error)
- RMSE(Root Mean Squared Error)
- Logloss(Cross Entorpy loss)
people mostly go with MSE.
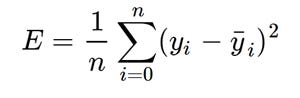
which is nothing but
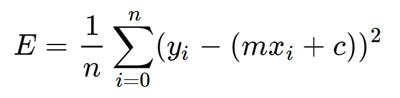
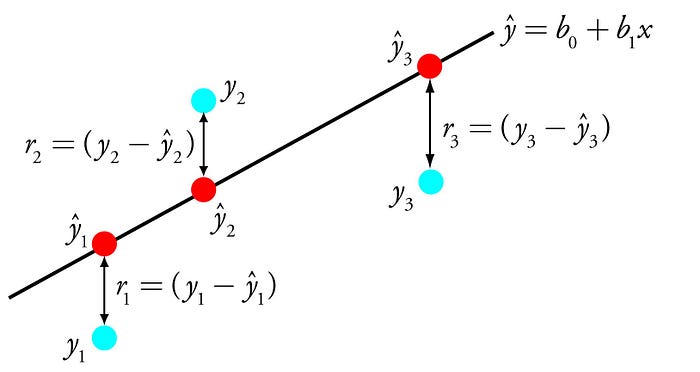
Where y1,y2,y3 are actual values and y`1,y`2,y`3 are predicted values.
now you got the Cost Function which means you got Error values. all you have to do now is to decrease the Error which means decrease the cost function.
But how do we Decrese the cost function?
By using Gradient Descent.
Gradient Descent:
We apply Derivation function on Cost function, so that the Error reduces.
- Take the cost function is
2. after applying Partial derivative with respect to “m” and “b” , it looks like this

3. now add some learning rate “alpha” to it.
note: do not get confused with notations. just write down equations on paper step by step, so that you wont get confused.
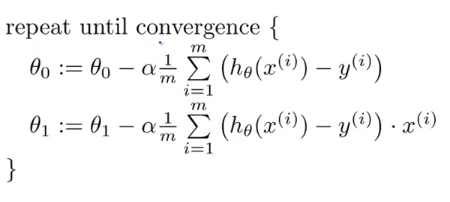
“theta0" is “b” in our case,
“theta1” is “m” in our case which is nothing but slope
‘m” is “N” in our case
and ‘alpha’ is learning rate.
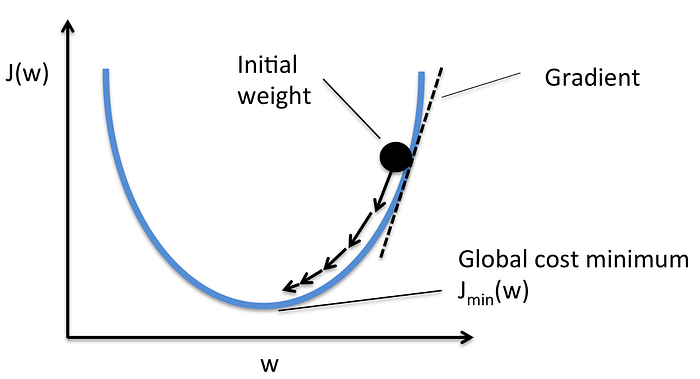
in 3d it looks like
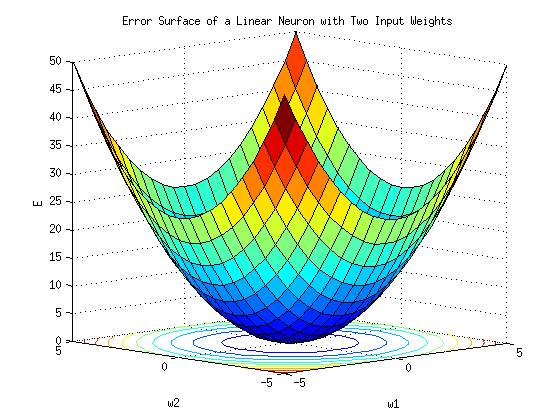
“alpha value” (or) ‘alpha rate’ should be slow. if it is more leads to “overfit”, if it is less leads to “underfit”.

still if you dont get what Gradient Descent is have a look at some youtube videos.
Done.
For simple understanding all you need to remember is just 4 steps:
- goal is to find the best fit for all our data points so that our predictions are much accurate.
- To get the best fit, we must reduce the Error, cost function comes into play here.
- cost function finds error.
- Gradient descent reduces error with “derivative funcion” and “alpharate”.
Now the interesting part comes. its coding.
CODE
For visualization and for more explanation check out the github repo here
You can comment your views. will be updated if any mistakes found. please feel free to comment down and as usual you can contact me linkedin below.
Thank you.